“龙虾之父”自曝惊人 Token 账单,大模型时代开始进入“词元通胀”
作者: CBISMB
责任编辑: 宋慧
来源: CBISMB
时间: 2026-05-18 10:42
浏览: 0
点赞: 0
收藏: 0
AI 行业对于 Token 的焦虑,正在从模型公司蔓延到整个开发者生态。
近日,被业内称为“龙虾之父”的知名 AI 开发者、长上下文架构研究者 Greg Kamradt 在社交平台公开晒出自己的 AI Token 消耗账单高达130万美元,引发全球开发者社区热议。由于其长期研究“大模型上下文工程(Context Engineering)”以及“Context Window”优化问题,在 AI 圈拥有极高知名度,因此不少开发者将其戏称为“龙虾之父”——这一称呼源自其此前广泛传播的“Lobster”长上下文实验项目。

Greg Kamradt 在公开内容中透露,仅部分 AI Agent 与长上下文实验任务,就消耗了极其夸张的 Token 数量,相关 API 成本远超传统开发者对 AI 调用费用的认知。尤其是在多 Agent 协同、长链式推理以及自动代码分析场景下,Token 消耗呈现指数级增长。
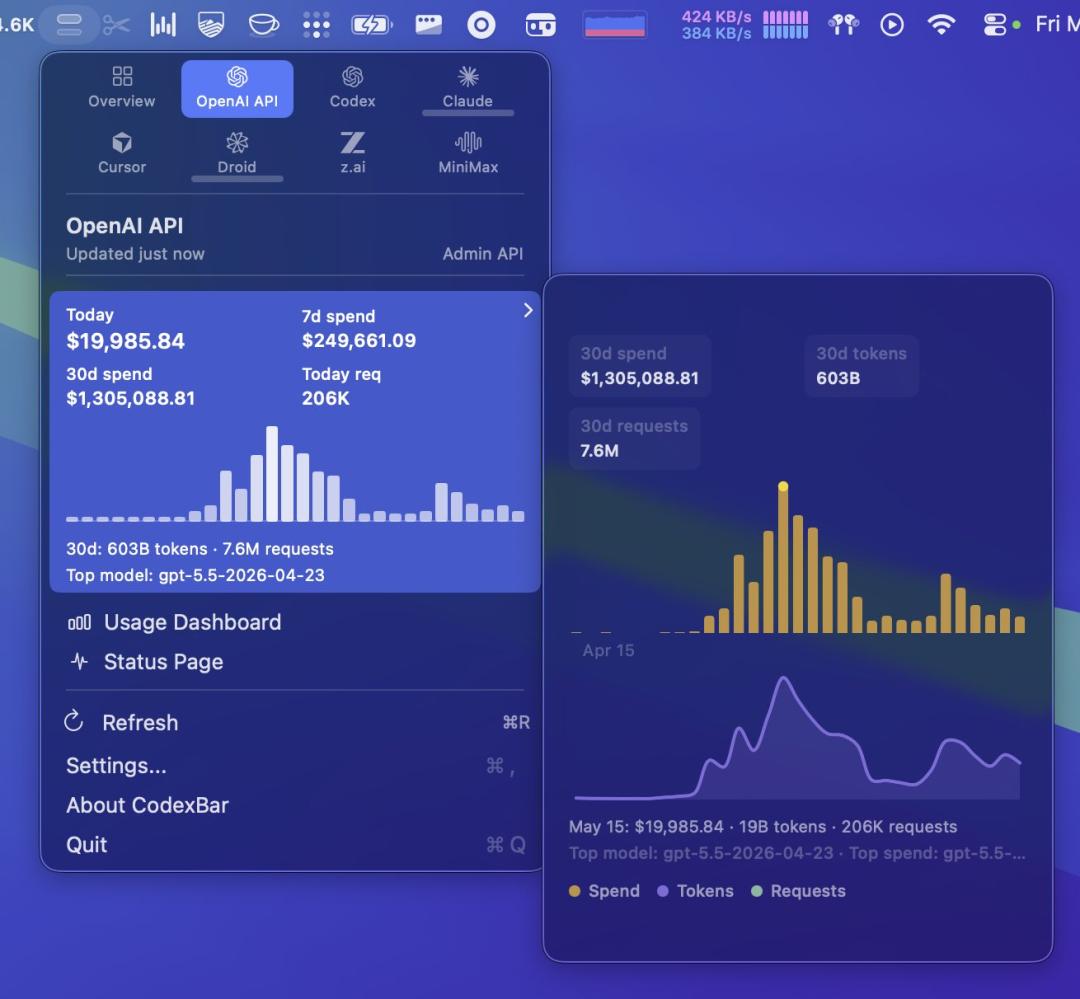
这一消息迅速引发开发者讨论,因为它揭示了一个正在被行业低估的问题:
大模型时代真正的“隐性成本”,正在变成 Token。
过去两年,AI 行业讨论最多的是模型参数、GPU 数量、推理速度、上下文窗口。
但随着 Agent 系统、自动编程、长期记忆以及多轮推理开始普及,越来越多开发者发现,一个 AI 系统真正烧钱的部分,并不只是模型本身,而是持续膨胀的 Token 消耗。
尤其是在长上下文模型出现之后,这种趋势正在变得更加明显。
此前,大模型通常只能处理几千 Token 的上下文,而现在,包括 OpenAI、Google、Anthropic 在内的主流 AI 公司,都已经开始支持数十万甚至百万级 Token 上下文。这使得 AI 能够阅读整本书、分析大型代码库、长时间维持记忆、执行复杂 Agent 工作流等,但与此同时,Token 成本也开始急剧上升。
因为在 Agent 系统里,Token 并不是“只输入一次”。
一次复杂任务往往意味着:多轮 Prompt、多模型调用、长链推理、记忆回放、工具调用结果回灌、多 Agent 相互通信等,每一步都在持续消耗 Token。
很多开发者开始意识到,一个复杂 AI Agent 的成本结构,已经越来越像“云计算账单”,而不再只是简单的 API 调用费用。尤其是在代码 Agent 领域,这种问题格外严重。
由于代码文件天然文本量巨大,一个大型项目可能轻易达到几十万 Token。当 AI 不断读取、分析、修改并重新生成代码时,Token 消耗会迅速暴涨。很多开发者原本以为:“AI 编程只是提高效率。”但真正落地后却发现:“AI 编程也可能带来惊人的 Token 成本。”
一些创业公司甚至开始重新评估:AI Copilot、自动编程 Agent、AI 办公助手等产品的商业模式。因为用户可能只看到了“一个对话框”,但后台实际上正在发生海量 Token 运算。
Greg Kamradt 这次公开 Token 账单之所以引发巨大关注,并不只是因为数字惊人,更因为它提前暴露了一个未来趋势:
随着 Agent AI 普及,Token 很可能会像今天的云计算资源一样,成为整个 AI 行业最核心、最昂贵、也最容易失控的基础资源之一。


